- Титульный лист
- Введение
- Глава I. Слово и его значение
- Глава II. Методы диахронического
исследования лексики
- 2.1 Подходы к диахроническому исследованию лексики
- 2.2 Словарь как источник для диахронической лексикографии
- 2.3 Корпус текстов как источник
для диахронической лексикографии
- 2.3.1 Методы работы с параллельными текстами
- 2.3.2 Материал
- 2.3.3 Выравнивание предложений
- 2.3.4 Составление лексических конкордансов
- 2.3.5 Статистический машинный перевод
- 2.3.6 Оценка статистических моделей
- 2.4 Выводы
- Глава III. Экспериментальное исследование эволюции экономической терминологии
- Заключение
- Список литературы
- Приложение
2.3.5 Статистический машинный перевод
При статистическом подходе проблема перевода рассматривается в терминах канала с помехами. Представим себе, что нам нужно перевести предложение с английского на русский. Принцип канала с помехами предлагает нам следующее объяснение отношений между английской и русской фразой: английское предложение представляет собой не что иное, как русское предложение, искаженное неким шумом. Для того чтобы восстановить исходное русское предложение, нам нужно знать, что именно люди обычно говорят по-русски и как русские фразы искажаются до состояния английского. Перевод осуществляется путем поиска такого русского предложения, которое максимизирует произведения безусловной вероятности русского предложения и вероятности английского предложения (оригинала) при условии данного русского предложения. Согласно теореме Байеса, это русское предложение является наиболее вероятным переводом английского:
![]() ,
,
где e – предложение перевода, а f – предложение оригинала
Таким образом, нам требуется модель источника и модель канала, или модель языка и модель перевода. Модель языка должна присваивать оценку вероятности любому предложения конечного языка (в нашем случае русского), а модель перевода должна присваивать оценку вероятности предложения оригинала при условии определенного предложения на конечном языке.
В общем случае система машинного перевода работает в двух режимах:
1. Обучение системы: берется тренировочный корпус параллельных текстов, и с помощью линейного программирования ищутся такие значения таблиц переводных соответствий, которые максимизируют вероятность (например) русской части корпуса при имеющейся английской согласно выбранной модели перевода. На русской части того же корпуса строится модель русского языка.
2. Эксплуатация: на основе полученных данных для незнакомого английского предложения ищется русское, максимизирующее произведение вероятностей, присваиваемых моделью языка и моделью перевода. Программа, используемая для такого поиска, называется дешифратором.
В качестве модели языка в системах статистического перевода используются преимущественно различные модификации n-граммной модели, утверждающей, что грамматичность выбора очередного слова при формировании текста определяется только тем, какие (n – 1) слов идут перед ним. Вероятность каждого n-грамма определяется по его встречаемости в тренировочном корпусе. Например, триграммная модель со сглаживанием оценивает вероятность грамматичности каждого слова z, следующего в тексте за словами x и y, по следующей формуле:
b(z | x y) = 0,95 * частота(«xyz»)/частота(«xy») +
0,04 * частота(«yz»)/частота(«z») +
0,04 * частота(«z»)/общее-число-слов +
0,002
Самой простой статистической моделью перевода является модель дословного перевода. В этой модели, известной как Модель IBM №1, предполагается, что для перевода предложения с одного языка на другой достаточно перевести все слова (создать «мешок слов»), а расстановку их в правильном порядке обеспечит модель языка. Единственным массивом данных, которым оперирует Модель №1, является таблица вероятностей попарных переводных соответствий слов двух языков:
| amount |
bonus |
compensation |
payment |
rate |
… |
|
| выплата |
15% |
8% |
6% |
71% |
0% |
|
| оплата |
0% |
0% |
0% |
97% |
3% |
|
| … |
Обучение Модели №1 производится на корпусе параллельных текстов, выровненном на уровне предложений. Математическая часть Модели №1 заключается в следующем [Knight, 1999]:
Вероятность предложения оригинала при данном предложении перевода:
![]() , где
, где
P(a, f | e) – это вероятность появления предложения оригинала f, выровненного с предложением перевода e на уровне слов способом a, при данном e.
![]() , где
, где
t – это вероятность слова оригинала в позиции j при соответствующем ему слове перевода eaj, определенном выравниванием a. Берется из таблицы вероятностей попарных переводных соответствий.
Для приведения P(a, f | e) к P(a | e, f), т.е. вероятности данного выравнивания при данной паре предложений, каждая вероятность P(a, f | e) нормализуется по сумме вероятностей всех выравниваний данной пары предложений:
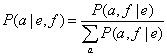
Имея набор выравниваний с определенными вероятностями, мы можем подсчитать частоты каждой пары слов, взвешенные по вероятности выравниваний, в которых они встречаются. Например, если какая-то пара слов встречается в двух выравниваниях, имеющих вероятности 0,5 и 1, то взвешенная частота tc такой пары равна 1,5.
Нормализовав эти взвешенные частоты по сумме вероятностей всех возможных переводных соответсвий e, получаем новые значения вероятностей попарных переводных соответствий:
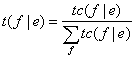
Реализация алгоритма Витерби, используемая для обучения Модели №1, состоит в следующем:
1. Вся таблица вероятностей переводных соответствий заполняется одинаковыми значениями.
2. Для всех возможных вариантов попарных связей слов вычисляется вероятность P(a, f | e):
3. Значения P(a, f | e) нормализуются для получения значений P(a | e, f)
4. Подсчитывается частота каждой переводной пары, взвешенная по вероятности каждого варианта выравнивания.
5. Полученные взвешенные частоты нормализуются и формируют новую таблицу вероятностей переводных соответствий
6. Алгоритм повторяется с шага 2.
Рассмотрим в качестве примера тренировку Модели №1 на корпусе из двух пар предложений:
- Белый Дом/White House
- Дом/House

После большого числа итераций мы получим следующую таблицу t:
| White |
House |
|
| Белый |
0,9999 |
0,0001 |
| Дом |
0,0001 |
0,9999 |
Слабость Модели №1 демонстрируется на простом примере: представим, что модель перевода предоставила нам следующий «мешок» слов: утром, вечером, деньги, стулья. С точки зрения модели языка предложения «Утром деньги, вечером стулья» и «Утром стулья, вечером деньги» будут, по-видимому, иметь примерно равную вероятность, однако один из вариантов явно искажает смысл. Кроме того, Модель №1 допускает ситуацию, в которой наиболее употребительным переводом нескольких смысловых слов может быть признано одно высокочастотное – например, служебное – слово конечного языка.
Чтобы сохранить при переводе информацию, заключенную в порядке слов, была предложена Модель IBM №2. В этой модели помимо таблицы переводов вводится таблица вероятностей обратных смещений, т.е. вероятностей, что при определенной длине предложения в языке перевода l и длине предложения в языке m оригинала слову перевода в позиции j будет соответствовать слово оригинала в позиции i. Например:
| Длина предложения перевода l |
Длина предложения оригинала m |
Позиция слова в переводе j |
Позиция слова в оригинале i, обусловленная l, m и j |
Вероятность |
| 10 |
10 |
1 |
1 |
70% |
| 10 |
10 |
1 |
2 |
20% |
| … |
||||
| 12 |
14 |
5 |
3 |
10% |
Модель №2 не допускает возможности, что одному слову оригинала соответствует несколько слов перевода. Этот недостаток устраняется в Модели №3, где вводится понятие коэффициента деления (fertility) слова оригинала и, соответственно, таблица вероятностей каждого значения коэффициента деления для каждого слова:
| Слово оригинала |
Коэффициент деления φ |
Вероятность |
| арбуз |
1 |
100% |
| не |
1 |
70% |
| не |
2 |
30% |
Помимо этого в Модели №3 используется понятие нулевого слова, которое, в соответствии с генеративной теорией Модели №3, с определенной вероятностью p порождает «необъяснимые» слова перевода. «Необъяснимыми» словами заполняются позиции, незанятые «нормальными» словами.
Модель №3 является одной из наиболее активно разрабатываемых – по-видимому, она достигает некоторого оптимального баланса между качеством порождаемых переводов (и объяснения фактических соответствий в двуязычном корпусе) и сложностью обучения. Однако эта модель не закрывает список классических статистических моделей перевода.
В Модели №4 и близкой к ней Модели №5 делается следующий шаг к включению понятий грамматики в систему статистического машинного перевода. В Модели №4 появляется понятие класса слов, определяемого автоматически для всех слов языка оригинала и языка перевода. Если в Модели №3 смещение зависело от позиции слова оригинала, длины исходного предложения и длины конечного предложения (в практических реализациях модели №3 последний аргумент не используется в связи с проблематичностью его вычисления a priori), то в Модели №4 смещение зависит от класса слов оригинала и перевода. В Модели №4 слова перевода делятся на заглавные (heads), незаглавные (non-heads) и производные от нулевого слова. Заглавное слово – это левое (первое) слово, связанное с определенным словом оригинала, незаглавное слово – это остальные слова, связанные с тем же словом оригинала (появляются только у слов с коэффициентом деления >1). Смещение заглавных слов определяется исходя из класса предыдущего слова оригинала и рассматриваемого слова перевода. Смещение незаглавных слов определяется на основе класса предыдущего слова в цепочке, зависимой от слова оригинала. Производные от нулевого слова, как и в Модели №3, расставляются случайным образом.
Обучение моделей №2 - №5 происходит аналогично Модели №1. Так как каждая итерация обучения более сложных моделей занимает существенно больше времени, чем для простых моделей, то обычно перед началом обучения сложных моделей производится несколько итераций младших моделей (начиная с первой), а потом их результаты преобразуются в формат более высоких моделей. Таким образом, оптимизация в старших моделях начинается не со случайного решения, а с некоторого решения, довольно близкого к оптимальному.
© Б.Н. Рахимбердиев, 2003.